
El Generative Media Team de Deepmind presenta su tecnología Google V2A (Video-to-Audio): Utilizan píxeles de vídeo como prompts de texto para generar «bandas sonoras enriquecidas»…
Los modelos de IA para generación de vídeo avanzan a un ritmo increíble, pero muchos sistemas actuales sólo generan una salida silenciosa. Uno de los próximos pasos importantes para dar vida a las películas obtenidas es la creación de bandas sonoras para esos vídeos que ahora son mudos.
El pasado Lunes 17 de Junio, Google Deepmind compartía sus progresos en cuanto a la tecnología V2A (Video-to-Audio), que posibilita la generación sincronizada de medios audiovisuales.
Y lo bueno de V2A es que combina píxeles de vídeo a modo de indicaciones de texto en lenguaje natural (prompts) para «generar paisajes sonoros enriquecidos para la acción mostrada en pantalla», aseguran sus creadores.
Prompt de audio para la obtención del vídeo superior: «Un baterista en el escenario de un concierto rodeado de luces intermitentes y una multitud que lo vitoreaba»
«Es posible combinar nuestra tecnología V2A con modelos IA para generación de vídeo como Veo; y a partir de eso, crear tomas con una partitura dramática, efectos de sonido realistas, o diálogos que coincidan con los personajes y el tono de un vídeo dado…» –Google Deepmind, Generative Media Team
Prompt de audio para el vídeo anterior: «Medusas pulsando bajo el agua, vida marina, océano»
Al parecer y según declaran, es igualmente posible generar bandas sonoras con Google V2A para una variedad de metraje tradicional; eso incluye material de archivo, películas mudas, y más, «lo cual abre una gama más amplia de oportunidades creativas», destacan sus desarrolladores.
Prompt de audio para el vídeo superior: «Lobo aullando a la luna»
Control creativo mejorado
Es importante destacar que Google V2A es capaz de generar una cantidad ilimitada de bandas sonoras (o resultados de sonido) para cualquier entrada de vídeo que se le proporcione.
Y como opción, es posible definir un «mensaje positivo» para guiar la salida generada hacia los sonidos deseados; o incluso un «mensaje negativo» para alejarlo de los sonidos no deseados.
«Esta flexibilidad brinda a los usuarios más control sobre la salida de audio de V2A, y eso permite experimentar rápidamente con diferentes salidas de audio y elegir la mejor combinación»
Fíjate en estos tres ejemplos oficiales, que surgieron como resultado de un refinado del prompt escrito para la obtención del audio:
Prompt de audio para el vídeo superior: «Una nave espacial se precipita a través de la inmensidad del espacio, las estrellas pasan como un rayo, alta velocidad, ciencia-ficción»
Prompt de audio para el vídeo superior: «Atmósfera etérea de violonchelo»
Prompt de audio para el vídeo superior: «Una nave espacial se precipita a través de la inmensidad del espacio, las estrellas pasan como un rayo, alta velocidad, ciencia ficción»
Las bases operativas de Google V2A (Video-to-Audio)
El sistema experimenta con enfoques autorregresivos y de difusión para descubrir la arquitectura de IA más escalable; y como resultado, «el enfoque basado en difusión para la generación de audio arrojó los resultados más realistas y convincentes para la sincronización de información de vídeo y audio», destaca el equipo de desarrolladores.
«Nuestro sistema V2A comienza codificando la entrada de vídeo en una representación comprimida. Luego, el modelo de difusión refina iterativamente el audio a partir del ruido aleatorio»
«Este proceso está guiado por la entrada visual y las indicaciones en lenguaje natural proporcionadas (prompt) para generar un audio realista y sincronizado, el cual es alineado estrechamente con la indicación. Y para acabar, la salida de audio es decodificada, convertida en audio, y combinada con los datos de vídeo»
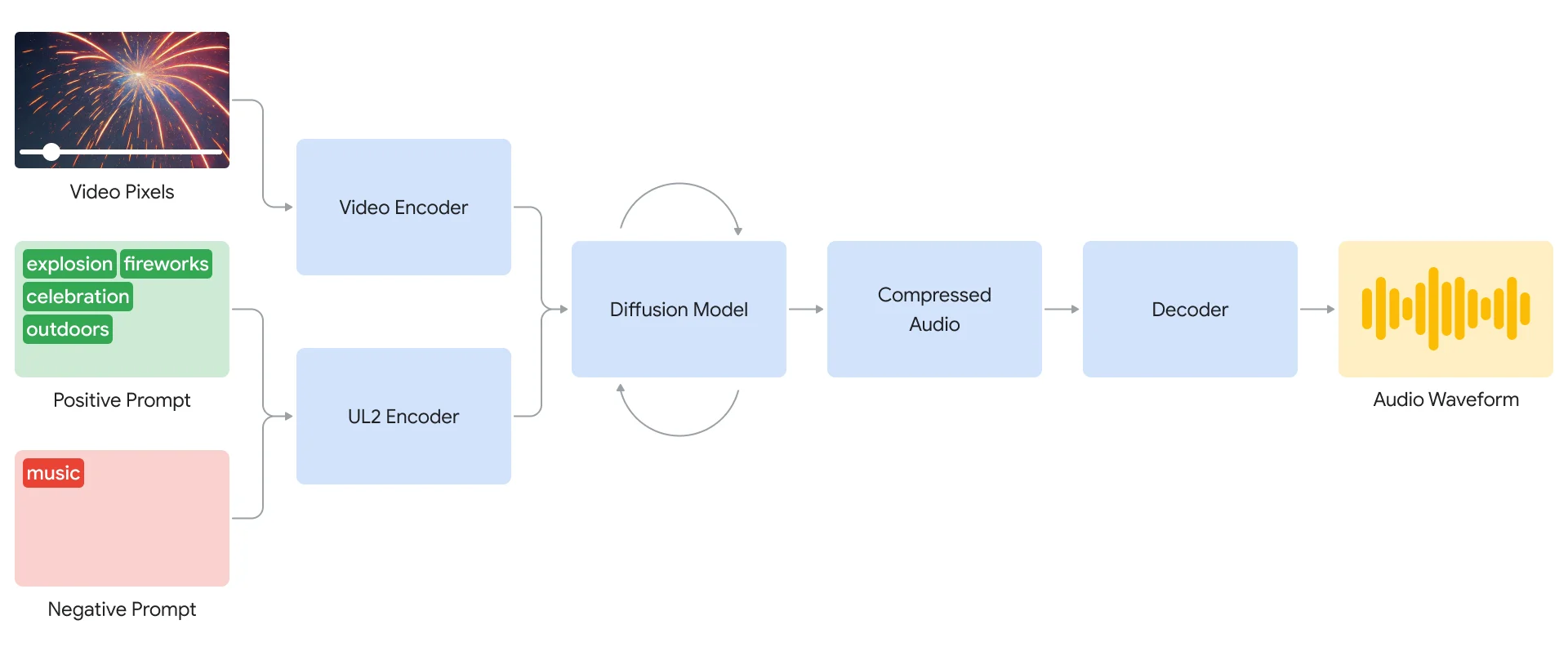
Para generar audio de mayor calidad y agregar la capacidad de guiar el modelo hacia la generación de sonidos específicos, V2A agrega más información al proceso de capacitación. Eso incluye anotaciones generadas por IA con descripciones detalladas de sonido y transcripciones de diálogos hablados.
Al entrenarse sobre archivos de vídeo y audio, además de anotaciones adicionales, la tecnología de Google V2A «aprende a asociar eventos de audio específicos con varias escenas visuales», mientras responde a la información proporcionada en las anotaciones o transcripciones.
Más allá de Google V2A –otras investigaciones en curso
Esta investigación sobresale frente a las soluciones existentes de vídeo a audio «porque es capaz de comprender píxeles sin procesar, y la agregación de un mensaje de texto [prompt] es un elemento opcional», dicen.
Además, el sistema no necesita alineación manual del sonido generado con el vídeo, lo que implica un ajuste siempre tedioso de los diferentes elementos de sonidos, imágenes y tiempos. Esto es algo que bien saben todos nuestros lectores Futuristas que editan vídeo.
Aún así, hay otras limitaciones que el equipo trata ahora de abordar, y para su solución están realizando más investigaciones.
La calidad de la salida de audio depende de la calidad de la entrada de vídeo, por ejemplo. Y por tanto, los artefactos o distorsiones en el vídeo que están fuera de la distribución de entrenamiento del modelo de Inteligencia Artificial, pueden provocar una caída notable en la calidad del audio.
«También estamos mejorando la sincronización de labios para vídeos que involucran habla. [Google] V2A intenta generar voz a partir de las transcripciones de entrada, y sincronizar ésta con los movimientos de los labios de los personajes»
«Pero el modelo de generación de vídeos emparejados puede no estar condicionado a las transcripciones. Esto crea una falta de coincidencia, que a menudo resulta en una extraña sincronización de labios, ya que el modelo de vídeo no genera movimientos de la boca que coincidan con la transcripción»
Prompt de audio para la obtención del vídeo superior: Música, Transcripción, ‘este pavo tiene un aspecto increíble, tengo mucha hambre’
El compromiso de Google Deepmind con la creatividad y la transparencia
Para asegurarse de que su tecnología V2A tenga un impacto positivo en la comunidad creativa (algo muy preocupante hoy), el equipo está recopilando diversas perspectivas e ideas a partir de creadores y cineastas líderes…
«Utilizamos estos valiosos comentarios para informar nuestra investigación y desarrollo en curso. Estamos comprometidos a desarrollar e implementar tecnologías de IA de manera responsable» –Google Deepmind, Generative Media Team
También incorporan su conjunto de herramientas SynthID en su investigación V2A para marcar con agua todo el contenido generado por IA.
Y sin duda, eso ayudará sobremanera a proteger a los creadores frente a los potenciales usos indebidos de esta apasionante tecnología.
Prompt de audio para la obtención del vídeo superior: «Cinemático, suspense, película de terror, música, tensión, ambiente, pisadas sobre hormigón»
Prompt de audio para la obtención del vídeo anterior: «Coches derrapando, acelerando el motor del coche, música electrónica angelical»
El acceso a Google V2A aún no es público
Antes de considerar abrir el acceso al público en general, esta tecnología V2A de Google Deepmind será sometida a rigurosas evaluaciones y pruebas de seguridad.
Los resultados iniciales cuyos vídeos alojados en YouTube ilustran este post, dejan ver que V2A proveerá un enfoque prometedor para dar vida a las películas generadas mediante Inteligencia Artificial.
Todos los ejemplos provistos fueron generados mediante las tecnologías Veo («nuestro modelo de vídeo generativo más capaz», dicen) y V2A, hábilmente combinadas por quienes mejor las conocen –sus propios creadores.